由於筆者對於數據分析都非常有興趣,也因為工作關係需要接觸到各種不同的雲端數據分析工具,繼上次筆者分享過「
透過Python與Spark做氣象大數據分析」是屬於IBM Bluemix的服務,這次筆者要分享的是關於2015年2月微軟推出的
Azure Machine Learning工具,有興趣的朋友可以從
這裡選擇「Guest Access」快速進行試用。或是申請一個
帳號,依照筆者的步驟執行,進行Microsoft Azure Machine Learning(MAML)的體驗。
過去在實務上經常發現要做一個數學模型與系統整合一起應用,是非常困難的一件事情,通常作法是需要先請統計學家設計好數學模型並驗證後,再交由軟體工程師進行系統整合,然後再依照市場需求做調整,再這樣反覆的過程中,統計學家改模型,軟體工程師調整系統,人力物力都消耗非常多。
在微軟這套Azure Machine Learning有幾個讓筆者覺得很方便的地方,筆者條列如下
- 應用模型即刻上線
- 多種現成應用選擇
- 採用拖拉互動介面
第一「應用模型即可上線」就是機器學習後的模型可反覆利用之外,還可快速佈署到雲端上,以筆者為例,要預測汽車價格,可在二十分鐘內完成模型佈署。第二「多種現成應用選擇」在Azure上有許多使用者分享了數學模型可以馬上使用,像是
預測汽車價格、
電影推薦、
更多......等。第三是「採用拖拉互動介面」介面使用容易,類似SPSS、SAS的概念,都是採用資料探勘的流程來進行資料分析。
接下來在本次的體驗中,我們採用最經典的
安德森鳶尾花卉數據集(Anderson's Iris data set)為例,並使用非監督式學習(Unsupervised Learning)方法中的K-means演算法來進行實作,以快速體驗雲端機器學習的便利性。
首先大家須先登入
Microsoft Azure的介面,目前Azure新版的介面只要使用到Azure Machine Learning都會跳轉到舊的介面,因此就參考筆者以下的畫面,照著操作即可。
首先選擇機器學習服務。
選擇「新增」,並點選「快速建立」,我們可以在工作區名稱上,建立自己的工作區名稱,像是ML這樣的名稱。
接著進入工作區之後,點選下方的「在Studio中開啟」的選項,進入MAML的使用介面。
接著我們必須點選「DATASETS」去上傳資料集,將資料做上船的動作,我們採用
這裡的資料,這是一份相當經典的示範資料集,只要到Google搜尋iris csv就有許多參考資料,資料中有150筆資料與5種資料欄位,下載之後我們點選「NEW」如下圖所示。
接著點選「FROM LOCAL FILE」將資料進行上傳的動作。
接著在介面上面直接「選擇檔案」,將檔案選好之後,點選右下角的勾勾,就可以進行上傳。
接著點選「EXPERIMENTS」,再點選下方的「NEW」。
接著我們會看到許多Machine Learning Samples,不過我們今天要自己做一個,所以點選「Blank Experiment」可以產生新的實驗環境。
接著看到工作區後,我們可以在下圖紅色框中輸入這個專案的名稱,像是筆者輸入「My First Azure Machine Learning Case」,接著就可以開始實作囉!
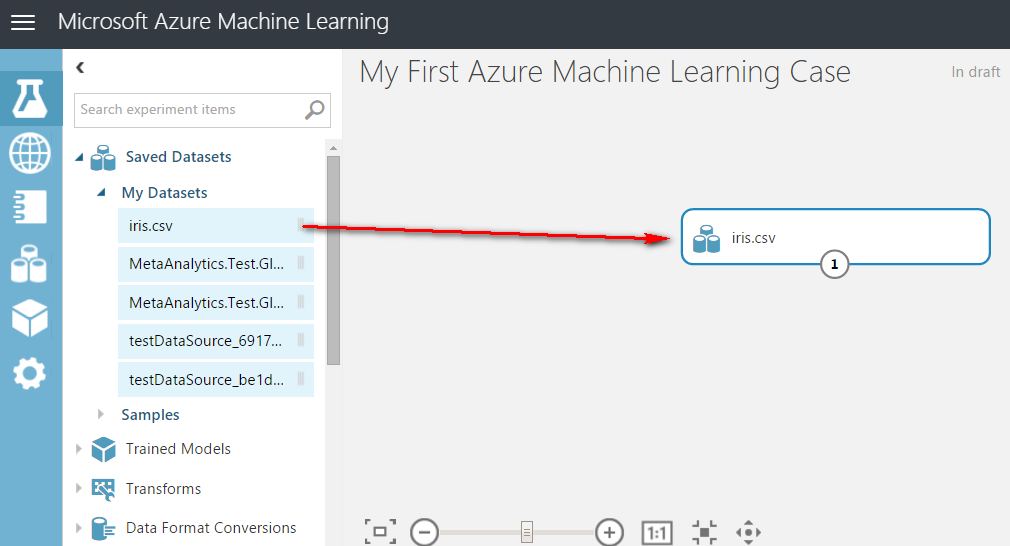
首先我們從「Saved Datasets」裡面的「My Datasets」將剛剛上傳的資料集「iris.csv」整個拖曳到右邊的工作區。
接下來我們可以很快的對這個資料集做資料視覺化(Visualization),這是筆者覺得滿方便的地方,使用者只要一個右鍵,就可以對資料集做初步的了解。
這個簡易的資料視覺化目前可以透過盒鬚圖(Box-plot)、長條圖(Bar Chart)、平均數(Mean)、中位數(Median)、最小值(Min)、最大值(Max)、標準差(Standard Deviation)......等統計資訊去觀察資料的狀況。
接著原始iris資料集裡面包含萼片長(Sepal length)、萼片寬(Sepal width)、花瓣長(Petal length)、花瓣寬(Petal width)、種類(Species)共五個欄位,我們先拿掉種類(Species)的欄位,這個欄位並不適合放在這個學習模型中,因此我們在下圖左邊紅框中搜尋「Project Columns」將他拖曳到工作區。
接著點選iris資料集的圓點,拖曳到「
Project Columns」的圓點,讓兩個功能做一個連線,如下圖所示
。
接著點選「Project Columns」,並點選右邊紅框的「Launch column selector」按鈕。
接著選擇「WITH RULES」→「ALL COLUMNS」→「Exclude」將「Class」欄位做排除的動作,如下圖示意。
因為一般來說,我們必須將資料分割成訓練集、測試集才能進行實驗,因此我們必須進行資料切割,這邊使用「Split Data 」,我們找到他之後,將他拖曳到右邊工作區。
接著一樣與Project Columns做連線。
接著我們點選「Split Data」的功能,輸入分割的比例,如下圖紅框所示,輸入0.7表示分割成訓練集70%,測試集30%,如果要分6/4就要輸入0.6,以此類推。
接著我們要有一個控制模型輸出的地方,找到「Train Clustering Model」之後一樣拖曳到右邊工作區。
接著我們將「Split Data」左下的訓練集(70%)拉到「Train Clustering Model」的右上角的圓點上,表示將訓練集放進去。
接著我們在Machine Learning裡面找到「
K-mean Clustering」這就是今天我們提到的非監督式學習(Unsupervised Learning)演算法的一種,我們將他拖曳到工作區。
將「K-mean Clustering」的圓點連線到「Train Clustering Model」的左上角圓點,表示我們要使用該演算法建立模型。
因為集群計算之後,都需要設定集群結果給資料集,所以我們要使用「Assign to clusters」這個功能配置模型預測結果。
接著將「Train Clustering Model」左下角的圓點,與「Assign to Clusters」上方的圓點進行相連。
最後我們要再使用「Project Columns」將運算結果輸出,所以一樣找到「Project Columns」然後拖曳到工作區。
接著我們會看到很多個元件上都有紅色驚嘆號,因為我們都還沒幫他設定資料的輸入或輸出。
不過沒關係,我們繼續將「Project Columns」再拖一個出來,將「Train Clustering Model」的右下角圓點與它做連線,這個動作主要是將原始的資料做輸出,不做也能完成實驗。
接著如上面所述,我們將「Train Clustering Model」與它做一個連線,如下圖所示
接著我們要開始針對這些放上去的元件做參數設定,我們先從「K-mean Clustering」開始,我們將他的中心數(K)設定為3個,也就是要分成3群。
接著我們點選「Train Clustering Model」的「Launch column selector」按鈕。
將他的輸入設定成包含萼片長(Sepal length)、萼片寬(Sepal width)、花瓣長(Petal length)、花瓣寬(Petal width)四個欄位,如下圖所示。
接著我們將「Assign to Clusters」右上角的圓點與「Split Data」右下角的圓點,也就是測試資料集做連接,如下圖指標所示。
接著我們選擇「Assign to Clusters」的「Launch column selector」按鈕,設定要使用的欄位。
一樣包含萼片長(Sepal length)、萼片寬(Sepal width)、花瓣長(Petal length)、花瓣寬(Petal width)四個欄位,如下圖所示。
接著我們對最後一個「Project Columns」做個設定。
注意這邊除了選擇包含萼片長(Sepal length)、萼片寬(Sepal width)、花瓣長(Petal length)、花瓣寬(Petal width)四個欄位之外,還要再選擇「Assignment」,如下圖所示。
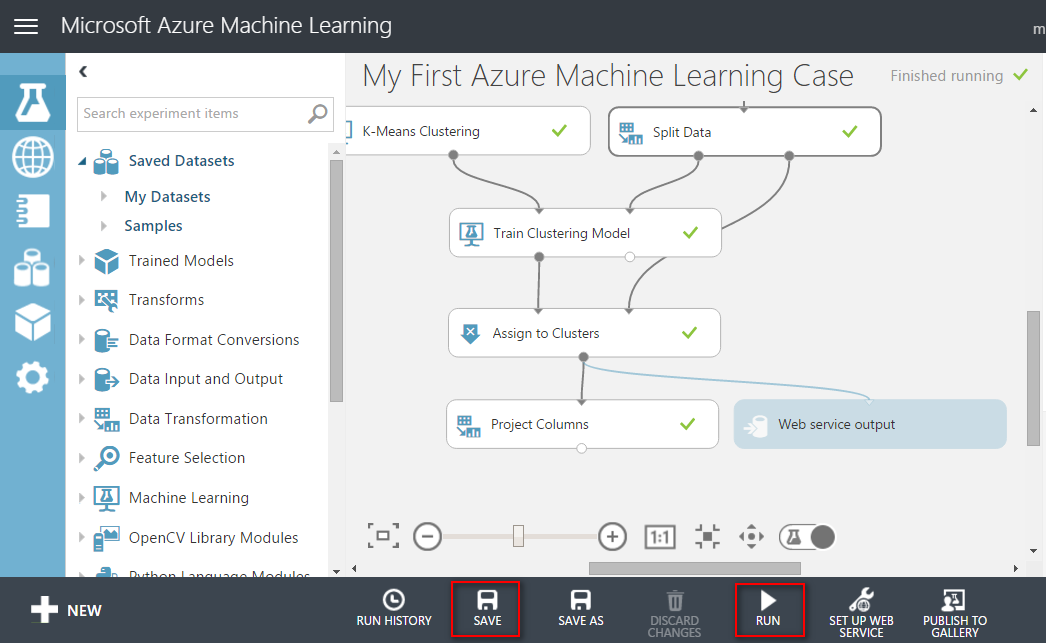
接著點選「SAVE」,再點選「RUN」。
接著會看到運行時間,因為資料不多,所以在幾秒內即可完成。
接著到這裡會出現下面錯誤,就是「Project Columns」找不到「Assignment」的問題,如下圖所示。
不過沒關係,我們只要到「Project Columns」裡面,再點選「Launch column selector」。
然後把剛剛選的「Assignment」刪掉再選一次即可,筆者推敲問題的原因是,模型還沒計算,所以第一次不會有「Assignment」的結果,所以要再設定一次。
接著再「SAVE」與「RUN」一次
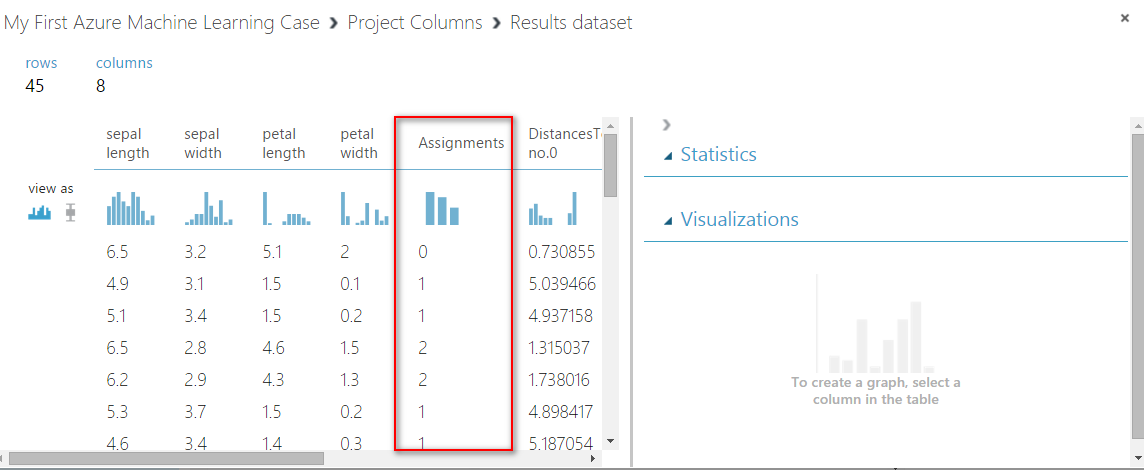
接著我們就可以點選「Project Columns」裡面的「Visualize」就可以看到分群的結果。
我們可以發現測試集的45筆資料,多了一個「Assignments」並且裡面分了0、1、2共三個群。
這就是我們初步的成果,不過還沒結束,接下來我們想把模型應用到系統上。
我們將要進行機器學習與系統整合這塊實作,在「Web Service」裡面,我們拖曳出「Input」。
接著將「Web service input」 與「Project Columns」做連接,表示新的資料有一部分會從這裡輸入。
接著我們將「Output」也拖曳到工作區,並將「Assign to Clusters」的下方圓點與「Web Service Output」做連接。
接著我們點選「SAVE」、「RUN」。
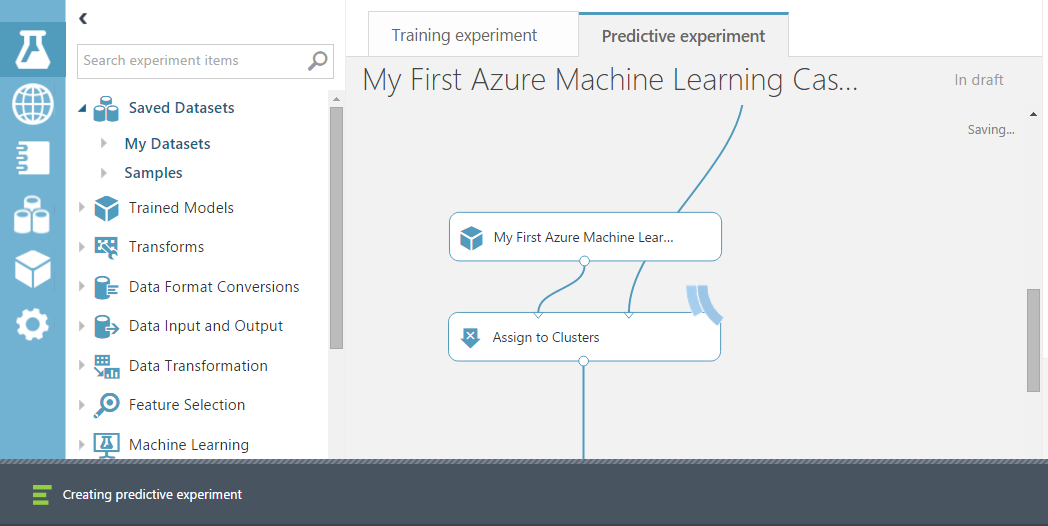
運算完之後,我們點選「SET UP WEB SERVICE」裡面的「Predictive Web Service」進行系統佈署前的設定。
接著可以看到Azure自動將我們的模型與系統做流程調整。
設定完之後,再做一次「SAVE」、「RUN」,將系統模型做儲存。
接著我們再點選一次「SET UP WEB SERVICE」就可以讓我們的演算法轉成API給系統使用,API全名為應用程式介面(Application Programming Interface),通常就是系統與系統間做傳輸共通標準,有了這個標準後,工程師不管寫甚麼系統,都可以直接透過API跟模型做連接,這個就是筆者覺得很方便的地方,因為這樣資料科學家就可以專注做模型即可。
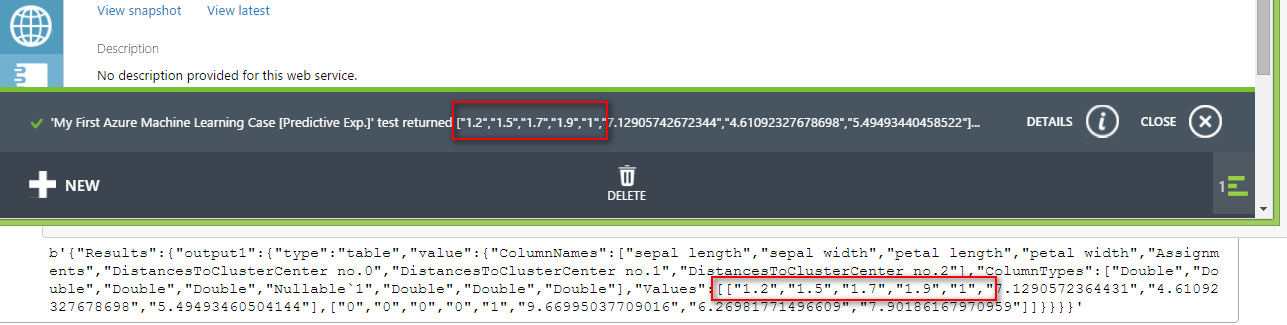
獲得API之後我們可以做一個簡單測試,點選「Test」。
我們嘗試在框框中輸入萼片長(Sepal length)、萼片寬(Sepal width)、花瓣長(Petal length)、花瓣寬(Petal width)四個欄位的新數字,也就是我們想要透過我們的模型去預測它的分群。
點選確認之後,我們就會在下方看到預測結果,筆者依次輸入1.2、1.5、1.7、1.9,他就被分到第1群(我們共有0,1,2三群)。
接著我們想要佈署到系統上,Azure很貼心的準備了C#、R、Python樣本程式碼,我們點選下圖左邊紅框的選項。
除了一些API使用說明之外,這裡就附上了三種語言的樣本檔案。
在每個程式碼當中,都需要加入api_key才能使用。
API KEY的內容可以參考筆者下方紅框中的資料,每個模型都有屬於自己的API KEY,所以不用拷貝筆者的。
接著做了替換之後,如果您是像筆者是寫Python 3,那就必須再做一些程式碼調整,如下圖紅框所示。
接著我們可以在Values裡面輸入我們想要預測的數字,執行之後就可以看到相同的結果。
下圖中,上面是用Test的結果1.2,1.5,1.7,1.8被分到第1群,下面使用Azure樣本python程式碼,一樣也是被分到第1群。
之後就可以把這段程式碼修改並佈署到相關的系統當中。
以上就是雲端機器學習的上手教學,希望能協助讀者做初步雲端機器學習體驗。